Style GAN Exordium
- 15 mins
Ever wondered how a letter combined from English and Hindi would look like? Or how the monalisa painted by Picasso look like? How the friend of yours would look in opposite gender or aged? Or how night king would look with different expressions?
With growing advancement in the field of Deep Learning, all this is not only possible, but relatively easy to do with the inference of a powerful neural network (rather than hours spent on Photoshop). The neural networks that make this possible are termed adversarial networks. Often described as one of the coolest concepts in machine learning, they are actually a set of more than one network (usually two) which are continually competing with each other (hence, adversarially), producing some interesting results along the way.
In this article we will dive deep in the Style Gan architecture and get our hands dirty with code by creating our own images exactly like This Person Doesn't Exist.com
Style Gan Introduction
StyleGAN was originally an open-source project by NVIDIA to create a generative model that could output high-resolution human faces. The basis of the model was established by a research paper published by Tero Karras, Samuli Laine, and Timo Aila, all researchers at NVIDIA.
But first, let's get a little intuition about GAN's
GAN Intuition
The basic components of every GAN are two neural networks - a generator that synthesizes new samples from scratch, and a discriminator that takes samples from both the training data and the generator’s output and predicts if they are “real” or “fake”.
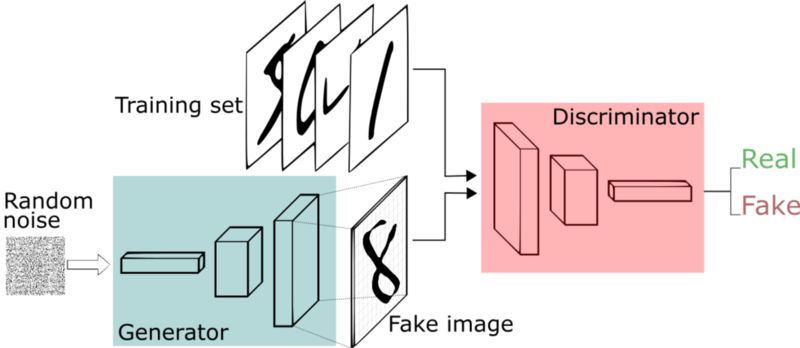
The generator input is a random vector (noise) and therefore its initial output is also noise. Over time, as it receives feedback from the discriminator, it learns to synthesize more “realistic” images. The discriminator also improves over time by comparing generated samples with real samples, making it harder for the generator to deceive it.
The loss function of GANs work on a Min-Max game. Where loss from the generator is minimized and that from the discriminator is maximised.
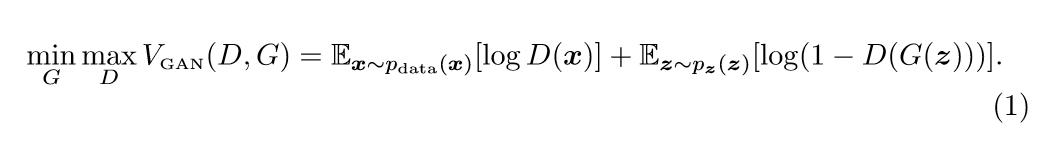
There was a lot of problem in generating high resolution images from this standard GAN method. To overcome this NVIDIA developed ProGAN or Progressive Growing Generative Adversarial Neural network.
Let's look into ProGAN architecture.
ProGAN Architecture
ProGAN works by gradually increasing the resolution , thus ensuring that the network evolves slowly, initially learning a simple problem before progressing to learning more complex problems(or, in this case, images of a higher resolution). This kind of training principle ensure stability and has been proven to minimize common problems associated with GANs such as mode collapse. It also makes certain that high level features are worked upon first before moving on to the finer details, reducing the likelihood of such features being generated wrong(which would have a more drastic effect on the final image than the other way around).
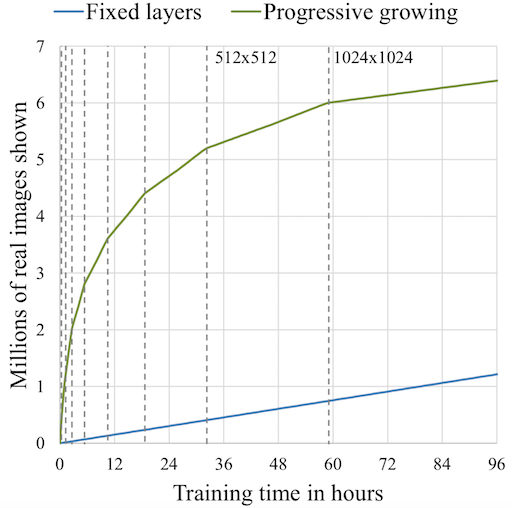
ProGAN works fast and is able to create high resolution images but, a short change in input affects multiple features at the same time. A good analogy for that would be genes, in which changing a single gene might affect multiple traits.
To overcome this, certain changes were made to make the Style GAN architecture more robust. Let's look at the changes made in the Style GAN architecture.
Style GAN
Style GAN architecture allows user to tune the hyperparameters. Moreover, due to addition of style at each convolution layer it allows for a factor of variability in generated images.
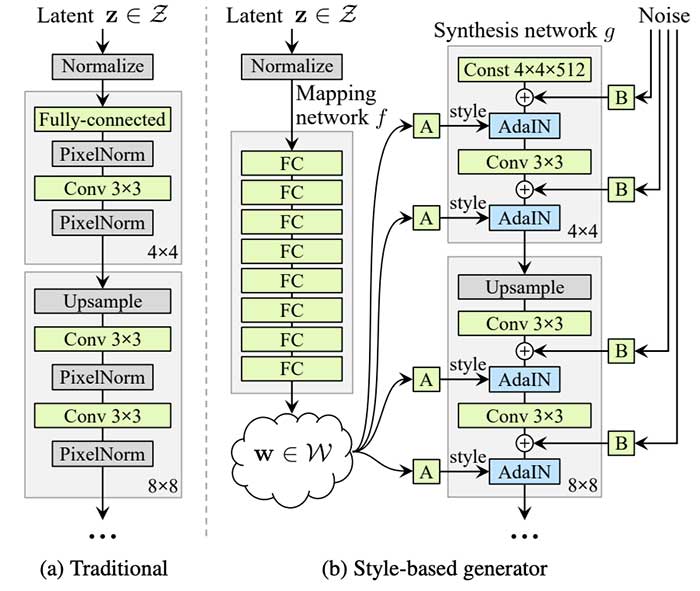
One point to be noted here is that all the changes in the Style gan architecture are done to the Generator part only. The Discriminator is left untouched.
Style GAN allows two images to be generated and then combined by taking low-level features from one and high-level features from the other. A mixing regularization technique is used by the generator, causing some percentage of both to appear in the output image.
At every convolution layer, different styles can be used to generate an image: coarse styles having a resolution between 4x4 to 8x8, middle styles with a resolution of 16x16 to 32x32, or fine styles with a resolution from 64x64 to 1024x1024.
These coarse styles govern the features and details like face shape, pose, hair style and minute details like eye colour or other microstructures.
Mapping Network
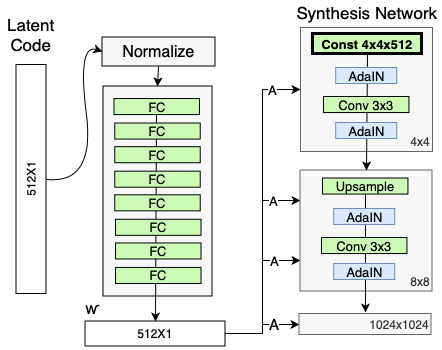
The Style GAN uses a mapping network to input a normalised vector W to the network. The mapping network as developed in the original NVIDIA Style GAN paper has 8 fully connected layers of 512X1 dimension.

The mapping network is used because the traditional GAN is unable to control the features and styles to a great extent. NVIDIA’s architecture includes an intermediate “latent space”, which can be thought of as being “detachable”. This gives an edge over traditional GAN architecture. The traditional GAN architecture is sort of biased according to the data set and causes a problem known as Feature Entanglement. A good example would be “entanglement” between the features of hair color and gender. If the dataset used for training has a general trend of males having short hair and females having long hair, the neural network would learn that males can only have short hair and vice-versa for females. As a result, changing the latent vector to obtain long hair for the image of a male in the result would also end up changing the gender, leading to an image of a woman.

Mapping network helps to overcome this issue of feature entanglement and generate realistic images.
ADAIN
A special layer ADAIN is used for addition of this mapping network output W to the synthesis network.The module is added to each resolution level of the Synthesis Network and defines the visual expression of the features in that level. Before adding to the synthesis network the ADAIN is also responsible for standardizing the mapping network output to standard Gaussian.

Removing Traditional Input-Noise
The traditional input that is noise is a gaussian noise and wraps around the complete mapping network space. But consider a situation where images of males and females are present in a data set and they are mapped according to the beard or no beard criteria. Females facial images are unlikely to have beards. A gaussian noise in this case would wrap around the complete feature space and thus would increase the input size where it is actually not needed. Moreover, the researchers found that the image features are controlled by W and the AdaIN, and therefore, considering both these cases the initial input can be omitted and replaced by constant values.
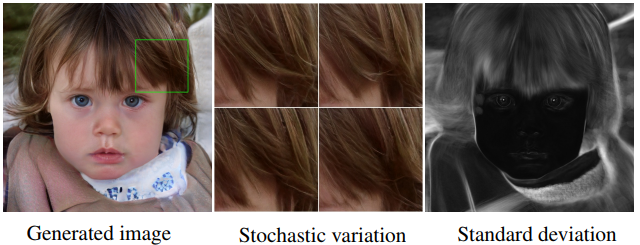
The StyleGAN architecture also adds noise on a per-pixel basis after each convolution layer. This is done in order to create “stochastic variation” in the image. The researchers observe that adding noise in this way allows a localized style changes to be applied to “stochastic” aspects of the image, such as wrinkles, freckles, skin pores, stubble, etc.
That's how we CODE!!!
After all this theory it's time to finally enter the FUN part... It's time to understand the code and implement our own Style GAN architecture.
First we sample a whole bunch of random vectors. We send them through a generator network and generate images, and once we have that dataset we can use resnet to go from the images to their respective latent codes.
So basically the model looks like this... A query image is taken(can be your own image) we pass it through a resnet and generate latent code from it. The latent code is passed through a generator and facial images are generated. These generated images are passed through a VGG network and semantic feature vector is generated. The semantic feature vector is a set of numbers generated by the VGG network before it's final layer. That is the VGG network is not completed. We extract the semantic feature vector from pre final layer or any layer before that.
The query image is taken and fed to a VGG network to generate semantic features from it.
These Feature vectors are taken and L2 distance is found out. This L2 distance is then minimized by running gradient descent. The gradients are send back into the latent code. One point to be noted here is that in all this process of backpropagation the generator weights are fixed, only the latent code at the input is updated.
YOU CAN TRY IMPLEMENTING YOUR OWN STYLE GAN AND GENERATE IMAGES. LINK PROVIDED BELOW CONTAINS THE CODE FOR THE SAME.
Abhishek Parashar
I make sense with data while having Pizza, Coffee and Freaky shakes.